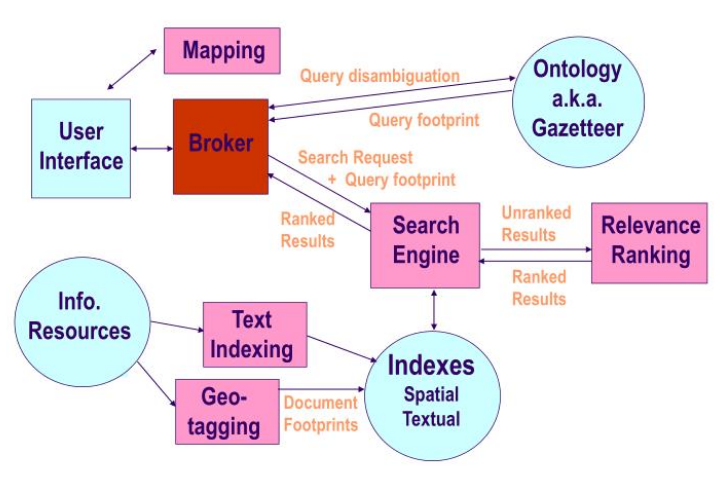
Information retrieval is about computing the degree of relevance between a set of objects, such as web pages, and the search parameters, e.g., keywords, specified by the user. Geographic Information Retrieval (GIR) adds space and sometimes time as dimensions to the classical retrieval problem. For instance, a query for “pubs in the historic center of Munster” requires a thematic and a spatial matching between the data and the user’s query. GIR considers the following steps. First, the geographic references have to be recognized and extracted from the user’s query or a document using methods such as named entity recognition and geo-parsing. Second, place names are not unique and the GIR system has to decide which interpretation is intended by the user. Third, geographic references are often vague; typical examples are vernacular names (“historic center”) and fuzzy geographic footprints. In case of the pub query, the GIR system has to select the correct boundaries of the historic center. Fourth, and in contrast to classical IR, documents also have to be indexed according to particular geographic regions. Finally, geographic relevance rankings extend existing relevance measures with a spatial component. The ranking of instances does not only depend on thematic aspects, e.g., the pubs, but also on their location, e.g., their distance to the historic center of Munster.
A Geographic Information Retrieval system must meet the following requirements:
Ambiguity in placenames comes in one of three forms:
The two most common approaches to disambiguation are rule-based (or knowledge driven) and data-driven (or corpus driven).
The following three methods have been used:
The data-driven methods of disambiguation generally apply standard machine learning methods to solve the problem of matching placenames to locations. However, a large enough corpus, that is annotated, does not exist in the public domain to apply supervised methods to free text.
The representation and storage of geographic data is an integral part of GIR. There are a number of approaches to indexing spatial data:
C-squares is built on the principle that the surface of the earth can be divided up into a grid of labeled squares (individual “c-squares”), at one of a range of scales, and that any type of dataset spatial extent can then be represented as a coded list of those squares in which the data occur. The grid system selected to form the basis of “c-squares” is the WMO (World Meteorological Organization) grid, which divides the world into 648 10 x 10 degree squares, each with a unique 4-digit identifier or code. C-squares extends this numbering system by recursive subdivision according to two sequences: a primary sequence at 10 x 10, 1 x 1, 0.1 x 0.1 degree squares, etc., and an “intermediate” set of subdivisions (quadrants) at 0.5 of each of these values - giving 5 x 5, 0.5 x 0.5, 0.05 x 0.05 degree squares, etc.
The Natural Area Code (or Universal Address) is a proprietary geocode system for identifying an area anywhere on the Earth, or a volume of space anywhere around the Earth. The use of thirty alphanumeric characters instead of only ten digits makes a NAC shorter than its numerical latitude/longitude equivalent. Instead of numerical longitudes and latitudes, a grid with 30 rows and 30 columns - each cell denoted by the numbers 0-9 and the twenty consonants of the Latin alphabet - is laid over the flattened globe. A NAC cell (or block) can be subdivided repeatedly into smaller NAC grids to yield an arbitrarily small area, subject to the ±1 m limitations of the World Geodetic System (WGS) data of 1984. A NAC represents an area on the earth—the longer the NAC, the smaller the area (and thereby, location) represented. A ten-character NAC can uniquely specify any building, house, or fixed object in the world. An eight-character NAC specifies an area no larger than 25 metres by 50 metres, while a ten-character NAC cell is no larger than 0.8 metres by 1.6 metres.
Given a number of search keywords and one or more locations that a user is interested in, a location-based web search retrieves and ranks the most textually and spatially relevant web pages. In this type of search, both the spatial and textual information should be indexed. Any index structure must be able to handle both the spatial and textual aspects of data simultaneously and accurately. Existing approaches either index space and text separately or use hybrid index structures. Moreover, these approaches need to accurately rank web-pages based on a combination of space and text. There are a number of approaches to hybrid indexing:
Given a set of documents D, each document d has a set of words Wd and is associated with a location Ld. Given a query q that has a set of query words Wq and a query spatial scope Sq. The textual and spatial relevance of a document d to a query q are defined as follows.
A document d is relevant if Wd ∩ Wq ≠ ∅ (Note: ∩ means overlaps)
To quantify the relevance of d to q, a function ϕq(d) is defined such that, if ϕq(d1) > ϕq(d2) then document d1 is more relevant than d2.
A document d is relevant if Ld ∩ Sq ≠ ∅
To quantify the relevance of d to q, a function φq(d) is defined such that, if φq(d1) > φq(d2) then document d1 is more relevant than d2.
There are a number of approaches to determine the spatial relevance of a document to a user's query, they fall into one of three: footprint methods, distance methods and topological methods
The footprint of a document can be defined as the polygon (minimum bounding rectangle or convex hull) drawn around the locations mentioned in the document. A query can also be represented as either a footprint or point and the relevance is then a measure of the area of overlap or the distance between the centroids of the polygons.
If a document is considered a collection of points, relevance between the query (also considered a point) and each point in a document is determined by the distance separating those points and is inversely proportional to the distance. There are many ways to calculate the distance between two points: a) Vincenty method, b) Haversine method, c) Euclidean metric and d) Manhattan metric, with the Vincenty method being the most accurate and the Manhattan metric being the least accurate.
Vertical topology represents the hierarchical nature of locations. For example, the Counties and States of the United States of America, the hierarchy of which can be represented as a directed graph. If all the locations on the same layer of a vertical topology graph are considered tessellating polygons, then a horizotal topology graph can be generated by connecting all nodes that share a border. The distance and overlap between locations found by navigating vertical and horizontal topology graphs can provide a measure of the relatedness of locations. Relevance can then be calculated based on the vertical and horizontal topologies and distance.
Ranking identifies those documents in D that are both textually and spatially relevant to q and returns the k most relevant documents sorted in descending order of their joint textual and spatial relevances denoted by ψq(d), where:
ψq(d) = α ϕq(d) + (1-α) φq(d) if ϕq(d) > 0 and φq(d) > 0
ψq(d) = 0, otherwise.
The weighting of the textual versus spatial relevance is defined by the parameter α, where 0<= α <= 1.0